DALL·E-2可以通过自然语言的描述创建现实的图像。Openai发布了dall·e-2的Beta版。在本文中,我们将仔细研究DALL·E-2的原始研究论文,并了解其确切的工作方式。由于并没有开放源代码, Boris Dayma等人根据论文创建了一个迷你但是开源的模型Dall·E Mini(命名为Craiyon),并且在craiyon.com上提供了一个DEMO。

在本文中,我们还将使用Meadowrun(一个开源库,可以轻松地在云中运行Python代码)把DALL·E Mini生成的图像输入到其他图像处理模型(GLID-3-xl和SwinIR)中来提高生成图像的质量,通过这种方式来演示如何将开源的ML模型部署到我们的云服务器上(AWS的EC2)。
DALL·E-2论文要点
DALL·E-2基于以前提出的unCLIP模型,而unCLIP模型本质上是对GLIDE模型[4]的增强版,通过在文本到图像生成流程中添加基于预训练的CLIP模型的图像嵌入。
与GLIDE相比,unCLIP可以生成更多样化的图像,在照片真实感和标题相似性方面损失最小。unCLIP中的解码器也可以产生多种不同图像,并且可以同时进行文本到图像和图像到图像的生成。
unCLIP框架
为了对给定的文本生成图像,提出了两阶段的过程:
1)使用先验编码器将文本编码到图像嵌入空间
2)使用图像扩散解码器根据图像嵌入生成图像。
由于它是通过反转CLIP图像编码器来生成图像的,因此本文将该框架命名为unCLIP。
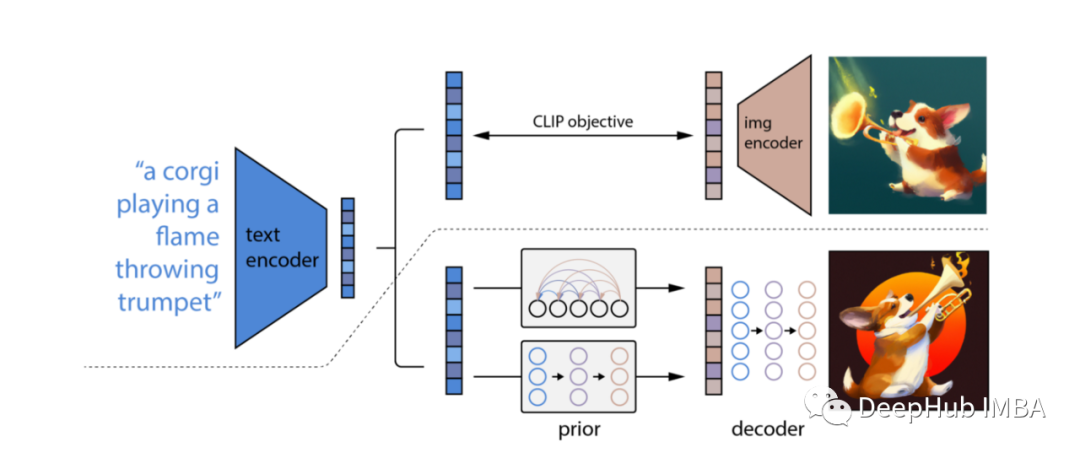
CLIP[3]可以共同学习文本和图像的表示形式,如上图(虚线上方)所示将一对(文本,图像)对相同的嵌入空间进行编码。
训练过程
给定一个(图像x,文本y)对,首先获取图像和文本嵌入,称为zᵢ= clip(x),zₜ= clip(y)。
先验:p(zᵢ| y,zₜ)产生图像嵌入zᵢ条件y。
解码器:P(X |Zᵢ,Y),根据图像嵌入zᵢ(和可选的文本标题y)产生图像。
p(x | y)= p(x | y,zₜ)= p(x |zᵢ,y)p(zᵢ| y,zₜ)
训练细节
使用CLIP数据[3]和DALL-E[2]数据(共计650M图像)进行训练。
VIT-H/16图像编码器:输入为256×256图像,总计32层transformers,嵌入尺寸为1280。
GPT文本编码器:具有1024个嵌入和24层transformers解码器。
CLIP Model训练完成后,先验模型、解码器模型和上采样模型都只在DALL-E数据集(总共约250M幅)上训练。
解码器模型是一个3.5B的 Glide模型,包含两个模块:1.2B 24层transformers文本编码器和2.3B的ADM模型。在训练期间,有50%的概率删除标题,有10%概率删除图像的嵌入。
为了生成高分辨率图像,作者训练了两个UPS采样器模型。两者都使用ADMNET体系结构。第一个将图像从64×64到256×256,第二个将图像从256×256到1024×1024。
对GLIDE 模型的改进
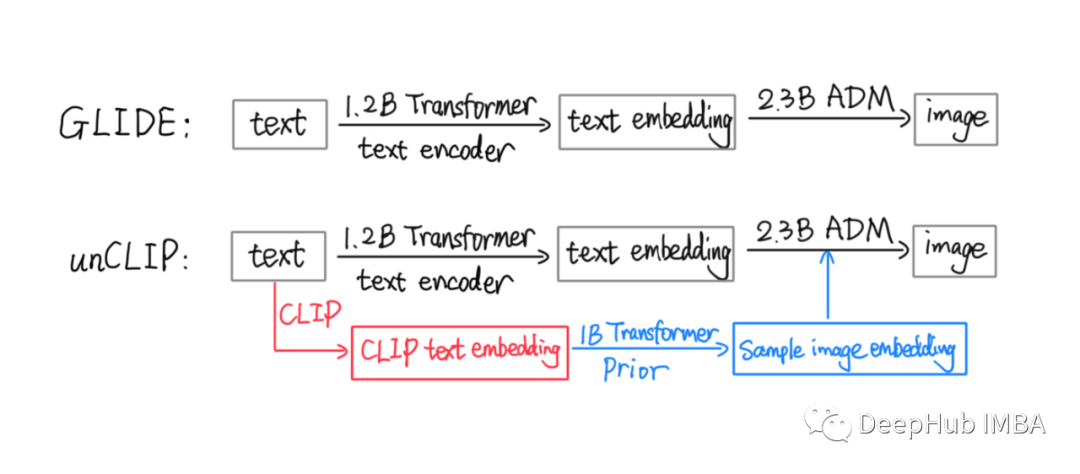
与Glide相比,Unclip通过训练先验模型进一步生成了一些示例图像嵌入。因此解码器(ADM模型)使用了所有输入,包括文本和“假”图像嵌入,生成最终图像。
上面我们对DALLE有了一个大致的介绍,下面我们看看如何部署我们自己的模型
部署dall·e mini(craiyon)
本文的这部分将介绍不需要$ 1,700 GPU,就可以部署自己的dall·e mini模型,我们将展示如何运行Saharmor/Dalle-Playground,并且将DALL·E Mini代码包装成一个HTTP API,然后通过一个简单的网页来调用该API生成图像。
Dalle-Playground提供了一个可以在Google Colab中运行的Jupyter Notebook。但是如果你想长期使用,有时候就会遇到COLAB的动态使用限制。这就需要你升级到Colab Pro(9.99/月)或COLABPRO+( 49.99/月),但是我们可以通过直接使用AWS,花几分钱就能搞定这个事。
前期准备
首先,你需要一个AWS账户。如果以前从未在AWS上使用过GPU实例则需要增加配额。AWS帐户在每个地区都有限制特定实例类型的配额。GPU实例配额共有4个:
L-3819A6DF:“所有G和VT实例请求”
L-7212CCBC:“所有P实例请求”
L-DB2E81BA:“按需运行G和VT实例”
L-417A185B:“按需运行P实例”
对于一个新的EC2帐户,这些都设置为0,所以如果你运行代码如果得到这个消息,说明需要首先申请配额
代码语言:javascript
复制
Unable to launch new g4dn.xlarge spot instances due to the L-3819A6DF quota which is set to 0. This means you cannot have more than 0 CPUs across all of your spot instances from the g, vt instance families. This quota is currently met. Run `aws service-quotas request-service-quota-increase --service-code ec2 --quota-code L-3819A6DF --desired-value X` to set the quota to X, where X is larger than the current quota. (Note that terminated instances sometimes count against this limit: https://stackoverflow.com/a/54538652/908704 Also, quota increases are not granted immediately.)可以点击上面的stackoverflow链接来了解如何请求增加配额。但是申请配额是需要审核的所以一般会要等1-2天。
然后就是需要安装Meadowrun。下面是一个在Linux中使用pip的例子:
代码语言:javascript
复制
$ python3 -m venv meadowrun-venv
$ source meadowrun-venv/bin/activate
$ pip install meadowrun
$ meadowrun-manage-ec2 install --allow-authorize-ips运行dall·e mini
上面准备完成后就可以运行Dalle-Playground的后端了
代码语言:javascript
复制
mport asyncio
import meadowrun
async def run_dallemini():
return await meadowrun.run_command(
"python backend/app.py --port 8080 --model_version mini",
meadowrun.AllocCloudInstance("EC2"),
meadowrun.Resources(
logical_cpu=1,
memory_gb=16,
max_eviction_rate=80,
gpu_memory=4,
flags="nvidia"
),
meadowrun.Deployment.git_repo(
"https://github.com/hrichardlee/dalle-playground",
interpreter=meadowrun.PipRequirementsFile("backend/requirements.txt", "3.9")
),
ports=8080
)
asyncio.run(run_dallemini())上面的代码功能如下:
- run_command告诉Meadowrun在EC2实例上运行Python Backend/app.py-port 8080 -model_version mini。这段代码使用Dalle-playground后端在端口8080上启动了Dall·e Mini的迷你版本。这个迷你版本比Dall·e Mini的超大(Mega)版本小27倍,虽然性能有一些损失,但是占用的资源很少,方便我们使用。
- 接下来的几行告诉Meadowrun我们对云服务的要求是什么:1 CPU,16 GB内存,并且我们申请的是能够接受概率80%中断的抢占实例,抢占实例可能会因为别人的高竞价而中断,如果不想被中断则可以将max_eviction_rate更改为0,也就是我们现在想要一个按需实例。但是因为按需的花费比较多,所以Dall·e Mini的最低要求是至少4GB GPU内存的NVIDIA GPU。
- 下面就是在https://github.com/hrichardlee/dalle-playground repo中下载代码,然后安装相应的python包,但是这里需要进行一个修改,以将jax [cuda]软件包添加到requiending.txt文件中。JAX是Google的机器学习库,大致相当于Tensorflow或Pytorch。
- 最后,就是在机器上打开8080端口,这样外部可以进行访问。
运行上面的代码,如果看到类似的输出,说明已经可以启动了实例
代码语言:javascript
复制
Launched a new instance for the job: ec2-3-138-184-193.us-east-2.compute.amazonaws.com: g4dn.xlarge (4.0 CPU, 16.0 GB, 1.0 GPU), spot ($0.1578/hr, 61.0% chance of interruption), will run 1 workersMeadowrun告诉我们这个实例将花费我们多少钱(每小时只有15美分!)
代码语言:javascript
复制
Building python environment in container eccac6...接下来,Meadowrun会基于我们指定的requirements.txt文件的内容构建一个容器。这会花费一些时间但是在构建完成后Meadowrun会对容器的镜像进行缓存(除非requirements.txt文件更改,否则不会重新构建)。但是如果有一段时间不用这个镜像,Meadowrun也会将其清理。
代码语言:javascript
复制
--> Starting DALL-E Server. This might take up to two minutes.如果你看到上面的消息,说明dalle-playground已经成功下载了,但是它需要进行几分钟的初始化。
代码语言:javascript
复制
--> DALL-E Server is up and running!这句话说明已经成功运行了,最后就是需要在本地机器上运行前端,然后调用我们刚才运行好的后端代码,如果你没有npm,还需要安装node.js:
代码语言:javascript
复制
git clone https://github.com/saharmor/dalle-playground
cd dalle-playground/interface
npm start在本地运行的前端页面中需要输入我们刚才构建的后端地址,例如http://xxx.us-east-2.compute.amazonaws.com:8080,如下图所示
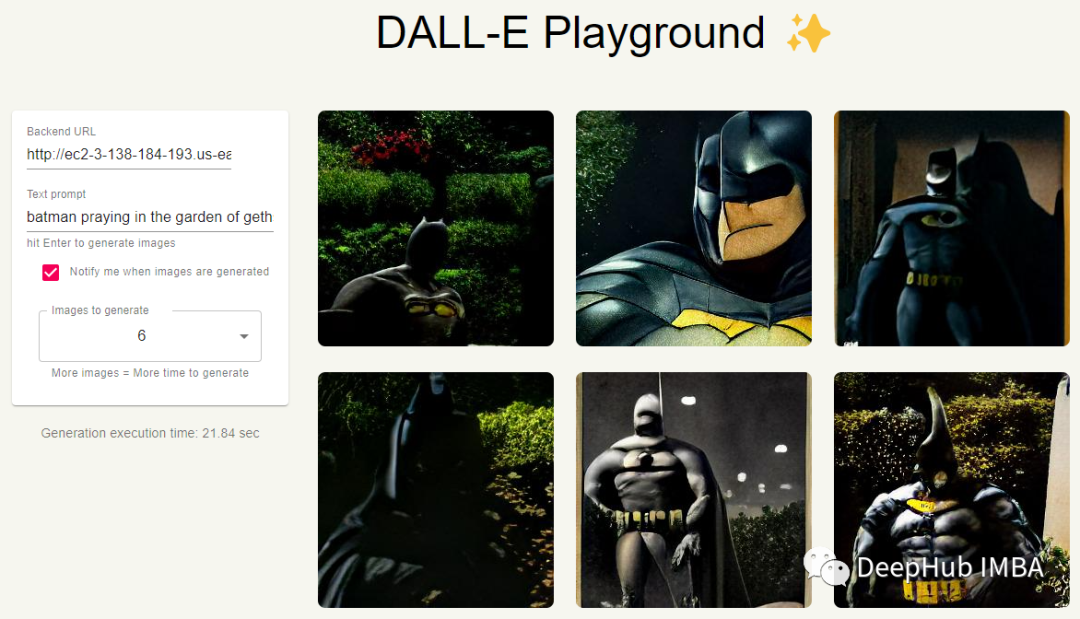
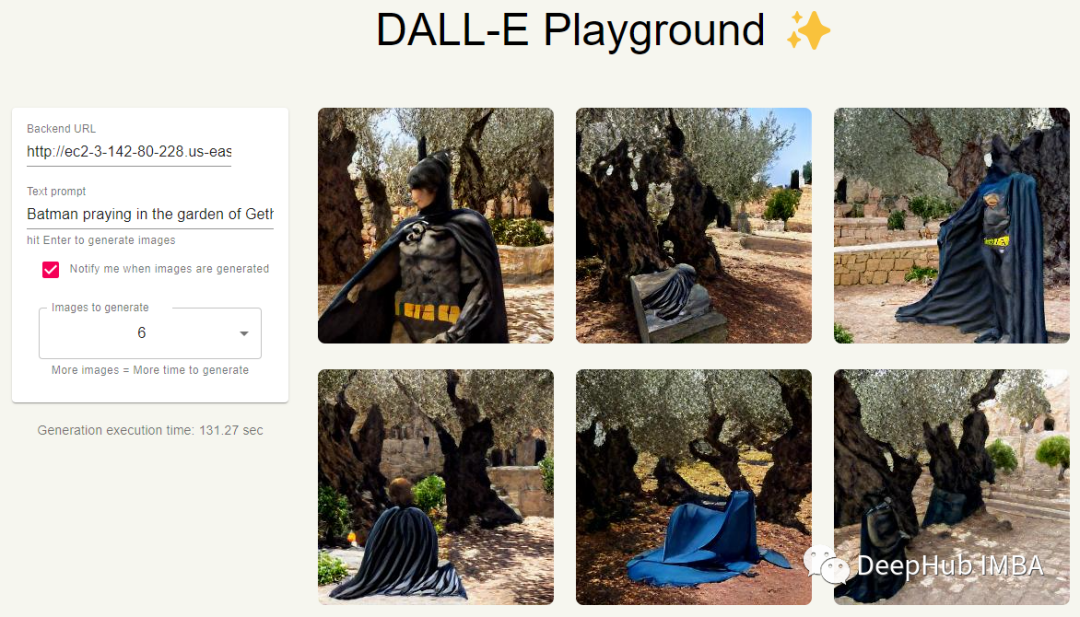
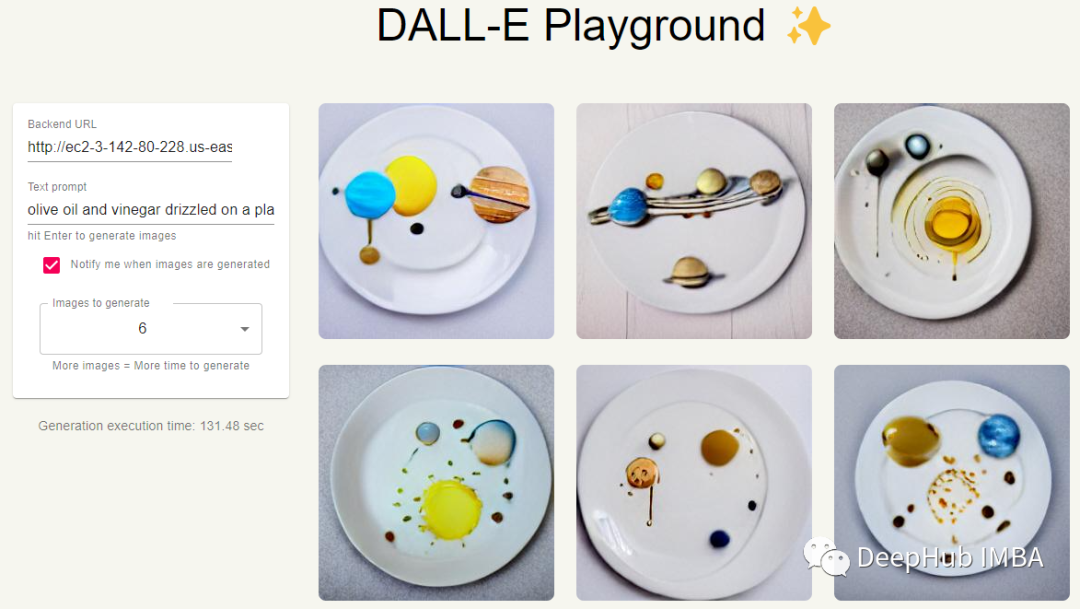
我们输入:olive oil and vinegar drizzled on a plate in the shape of the solar system,看看结果
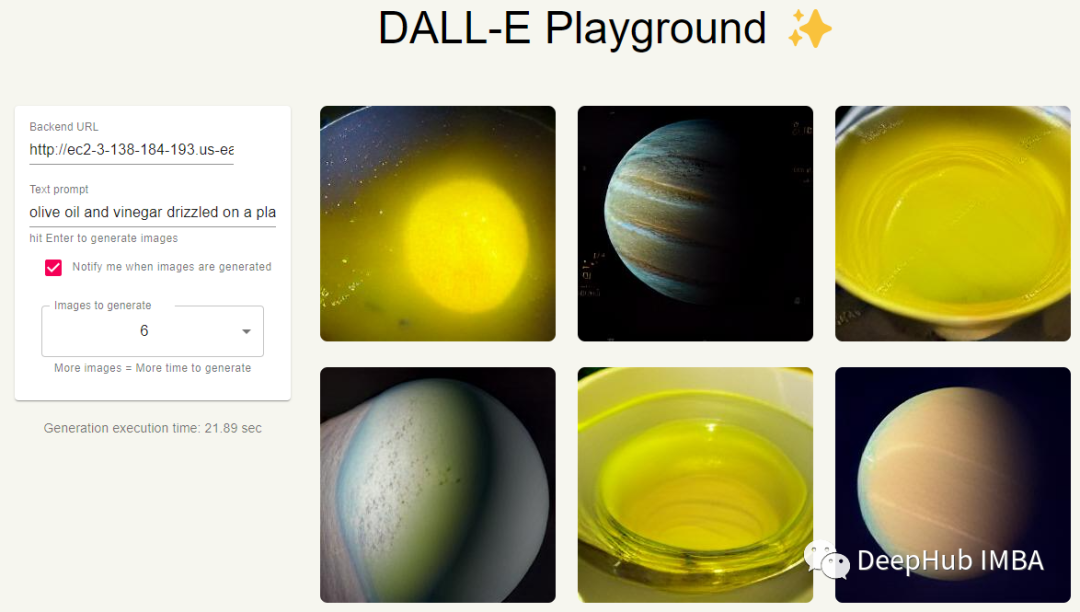
我们自己的服务已经正常的运行了,现在看看效果,在第一组图像中,我们显然有一个蝙蝠侠般的人物,但他并没有真的在祈祷。在第二组图像中,看起来我们要么得到橄榄油,要么得到行星,但他们也没有在同一幅图像中同时出现。这可能是因为我们用的是迷你版的原因,下面让我们看看“超级”版本的DALL·E Mini是否能做得更好。
DALL·E Mega
dall·e Mega是Dall·e Mini的超大版本(超大杯),这意味着它们的体系结构相似,但参数更多。从理论上讲,我们可以在上面代码中-model_version mega_full替换 - model_version mini就可以。但是这样Dalle-playground初始化代码大约需要45分钟。因为Mega版的预训练文件有10GB而我们下载的带宽只有35 Mbps。
为了省钱我们对Dalle-playground进行了一些调整,将模型先缓存到S3中,再从S3中下载。cache_in_s3.py可以调用wandb.Api().artifact(" dale -mini/ dale -mini/mega-1:latest").download()下载预训练模型,然后上传到S3中。
要使用S3我们就要创建一个S3 bucket,并赋予Meadowrun EC2角色访问它:
代码语言:javascript
复制
aws s3 mb s3://meadowrun-dallemini
meadowrun-manage-ec2 grant-permission-to-s3-bucket meadowrun-dalleminiS3 bucket名称需要全局惟一,然后使用Meadowrun在一台更便宜的机器上启动长时间运行的下载任务,下载很简单,只需要很小的内存,也不需要GPU:
代码语言:javascript
复制
import asyncio
import meadowrun
async def cache_pretrained_model_in_s3():
return await meadowrun.run_command(
"python backend/cache_in_s3.py --model_version mega_full --s3_bucket meadowrun-dallemini --s3_bucket_region us-east-2",
meadowrun.AllocCloudInstance("EC2"),
meadowrun.Resources(1, 2, 80),
meadowrun.Deployment.git_repo(
"https://github.com/hrichardlee/dalle-playground",
branch="s3cache",
interpreter=meadowrun.PipRequirementsFile(
"backend/requirements_for_caching.txt", "3.9"
)
)
)
asyncio.run(cache_pretrained_model_in_s3())然后就是修改模型代码,让它从S3而不是从wandb下载文件,并且我们使用/meadowrun/machine_cache文件夹,该文件夹可以在一台机器上由meadowrun的所有容器共享。这样在同一台机器上多次运行同一个容器,就不需要重新下载这些文件了。
代码语言:javascript
复制
import asyncio
import meadowrun
async def run_dallemega():
return await meadowrun.run_command(
"python backend/app.py --port 8080 --model_version mega_full --s3_bucket meadowrun-dallemini --s3_bucket_region us-east-2",
meadowrun.AllocCloudInstance("EC2"),
meadowrun.Resources(1, 32, 80, gpu_memory=12, flags="nvidia"),
meadowrun.Deployment.git_repo(
"https://github.com/hrichardlee/dalle-playground",
branch="s3cache",
interpreter=meadowrun.PipRequirementsFile("backend/requirements.txt", "3.9")
),
ports=8080
)
asyncio.run(run_dallemega())最后需要注意的是:Meadowrun的安装会设置了一个AWS Lambda并且定期运行,如果有一段时间没有运行作业,它会自动清理实例。当然你也可以手动清理实例,命令如下:
代码语言:javascript
复制
meadowrun-manage-ec2 clean下面看看效果:
看样子很不错了,但是这些图像还不能与OpenAI的DALL·E相提并论,因为我们自己也没法像OpenAI的DALL·E那样训练模型,但我们可以尝试添加一个扩散模型来改进图像中的更精细的细节。我们还将添加一个模型来放大图像,因为它们现在只有256x256像素。
构建我们自己的图像生成模型
在本文的后半部分,我们将使用meadowdata/meadowrun-dallemini-demo,来优化模型生成的图像,这个想法来自于 jina-ai/dalle-flow。
DALL·E Mini:我们在文章的上半部分已经做了介绍了,DALL·E是两种模型的组合。第一个模型以图像为训练对象,学习如何将图像“压缩”为向量,然后将这些向量“解压缩”回原始图像。第二个模型在图像/标题对上进行训练,并学习如何将标题转换为图像向量。训练结束后,我们可以在第二个模型中输入新的文本并产生一个图像向量,然后将该图像向量输入到第一个模型中,产生一个新的图像。
GLID-3-xl:扩散模型。扩散模型是通过,模糊(又名扩散)图像并在原始/模糊图像对上训练模型来训练的。该模型学会从模糊版本重建原始图像。扩散模型可用于各种任务,我们这里将使用GLID-3-XL优化图像中的细节。
SwinIR:图像缩放模型(又叫图像恢复)。图像恢复模型是通过对图像进行降尺度处理来训练的。该模型学习从缩小后的图像产生原始的高分辨率图像。
代码语言:javascript
复制
git clone https://github.com/meadowdata/meadowrun-dallemini-demo
cd meadowrun-dallemini-demo
# assuming you are already in a virtualenv from before
pip install -r local_requirements.txt
jupyter notebook我们编辑S3_BUCKET_NAME和S3_BUCKET_REGION,以匹配在上面中创建的存储桶。
我们这里对一些重要的代码所做简单的注释:
调整了所有模型随附的示例代码增加了S3缓存的部分,并在dalle_wrapper.py,glid3xl_wrapper.py和swinir_wrapper.py中提供易于使用的接口。
所有模型在Linux以外的任何其他操作上都可能无法运行,所以将local_requirement.txt从model_requirentess.txt分开,这样在Windows或Mac上也都没有问题了 。
现在这些模型是作为批处理作业来运行的,Meadowrun将重用单个EC2实例。如果你有兴趣(钱)也可以使用meadow.run_map在多台GPU机器上并行运行这些模型。
让我们看看结果吧!DALL·E Mini生成8张图片:

我们选择一张图片,GLID-3-xl会根据选择的图片生成8张新的图片。

然后我们选择其中一张图片,并将其从256x256升级到1024x1024像素:

看着还不错啊,
以下是OpenAI的DALL·E相同的内容:


看看另外一个的比较:

这是OpenAI的


OpenAI的DALL·E的效果还是最好的,毕竟大力出奇迹么。但是经过我们优化的DALL·E Mini也还过的去,毕竟是开源的并且随着不断的训练它会变得更好。
总结
这篇文章介绍DALL·E-2论文的一些要点,并且演示了如何使用Meadowrun来部署他的一个开源版本的实现,如果你有兴趣,可以按照我们提供的流程搭建一个属于自己的图像生成服务。
* 本站资源均收集整理于互联网,其著作权归原作者所有,如果有侵犯您权利的资源,请来信告知,我们将及时撤销相应资源。